JVx and MySQL, Limited Edition
If you work with JDBC and MySQL, you will most likely be aware of one shortcoming: MySQL can not stream the results from a query (well, actually it can, but the feature is quite limited). That means that up until now JVx has always received and stored the full result set in memory which it received from MySQL. No paging was performed as it was done in the Oracle implementation.
Limit to the rescue!
MySQL does support the limit clause, which allows to limit the results to either a certain number of rows, or a certain range of rows. How does it look like?
ID,
NAME
FROM
TEST
WHERE
NAME LIKE 'Hans%'
LIMIT 5, 10;
This will fetch the data starting by the 5th row up to the 15th row, so it will skip the first five rows and then return the next ten. As this is a database builtin, no additional data is send over the wire except the actual requested rows. This is perfect if you want to limit your queries, for example, because you know that you don't need more than 5 rows even though there are 50,000 rows.
Fetch all the things!
With the old behavior, without limit clause, the JDBC MySQL driver would fetch the complete result of the query and only we would do some cutting on it (mainly dropping not needed rows at the start). That meant that the complete result set was always loaded into memory, which itself might have caused that you were unable to execute certain queries, especially if they contained bigger blob columns.
Limit all the things!
With the new behavior, the limit clause is appended to the query as needed, which means that the JDBC MySQL driver has to load a lot less data and a lot less data is send over the wire.
The MySQL giveth, the MySQL taketh away...
But there is an additional cost associated with the usage of the limit clause. Because the fetches are separate statements, all rows leading up to the beginning row have to be selected, too. Let us return to our first example, the query of the TEST table. We only want 10 rows starting from the 5th row, that means our result set only contains 10 rows. However, MySQL has (obviously) to query, select and discard the first five rows so that it can start sending us the rows that we actually want. That means that the cost of selecting pages increases. Off to pretty graphics!
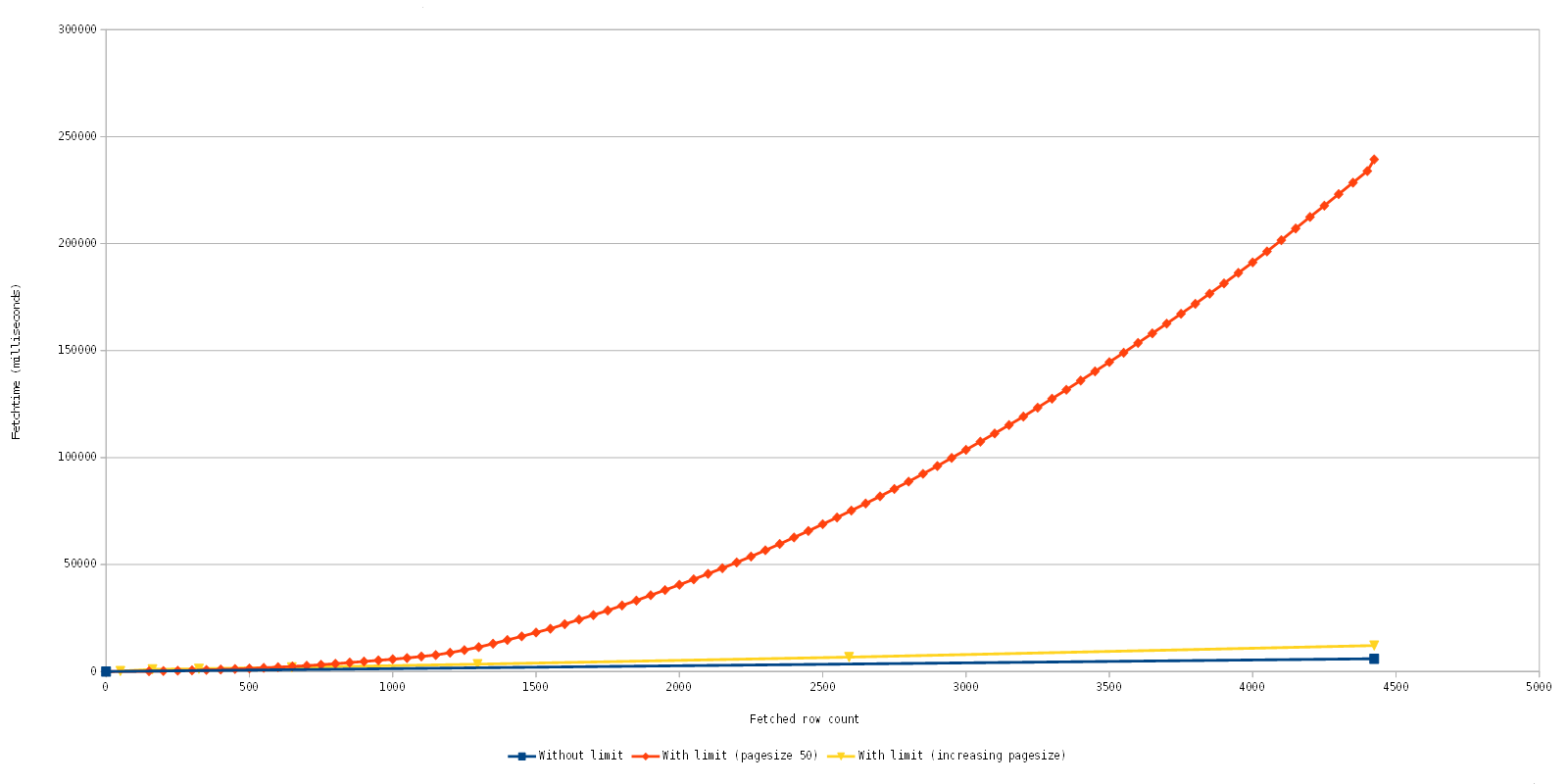
Note that the fetch time is accumulative.
- Blue: The original implementation which does perform only one fetch of all data. In this case it is quite fast, but depending on the query and data you could wait a long time for the initial fetch, if it was possible at all.
- Orange: The current implementation with quite a worst case scenario, it gradually fetches page after page with a row count of 50. As you can see the fetch time gradually increases, but as you can also see the initial fetches are fast.
- Yellow: An optimization experiment which increases the fetched row count dynamically.
Let us look at this again in detail, to be exact the fetching of the first 1500 rows.
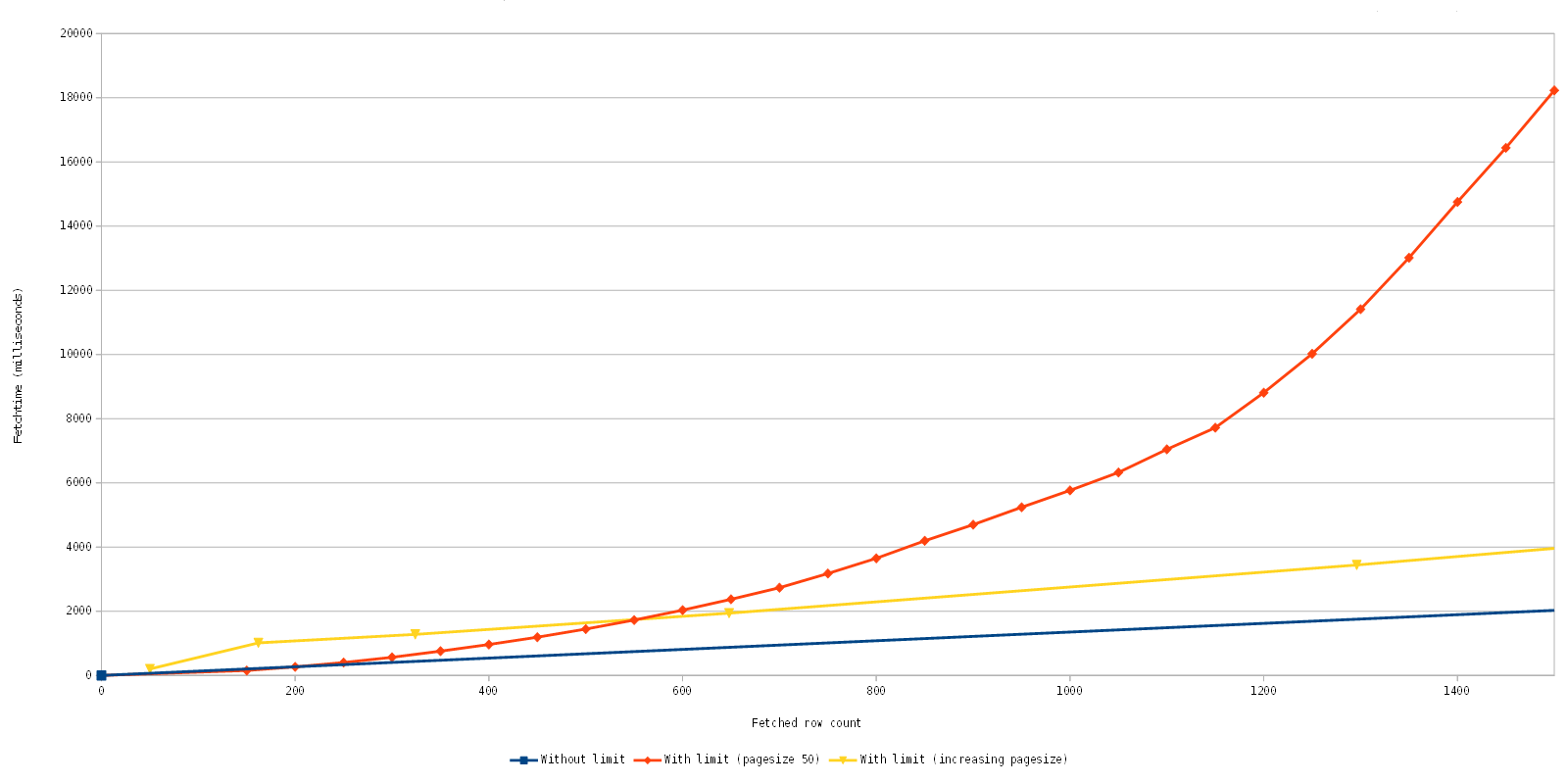
What we see here is quite good news, actually, because with the new implementation with the limit clause, you can consecutively fetch 600 rows in the same time as the fetching of the 4400 rows with the old implementation. The big difference here is that the first set of ~113 rows returns close to immediately and consecutive fetches are equally fast. This is awesome because we can now display initial data faster, even few it is fewer data in the end and slows down the more data is fetched afterwards.
Improve all the things!
As you can see from the charts, we already did a short experiment to improve this further, and we are confident that we can implement such a solution which dynamically fetches more rows to reduce the overall fetch time while still preserving that the first rows are displayed fast, further improving GUI responsiveness.
![]() Development, Information | rzenz | 22/04/2016 |
Development, Information | rzenz | 22/04/2016 | ![]() Comments (0)
Comments (0)
 RSS-Feed
RSS-Feed