JVx Reference, of Technologies and Factories
Let's talk about the UI layer, the implementations and the factory that powers it all.
The basics
For everyone who does not know, JVx allows you to write code once and run it on different GUI frameworks, without changing your code. This is achieved by hiding the concrete GUI implementations behind our own classes, the UI classes, and providing "bindings" for different GUI frameworks behind the scenes. Such a "Single Sourcing" approach has many advantages, and just one of them is that migrating to a new GUI framework requires only the change of a single line, the one which controls which factory is created.
The Factory Pattern
The Factory Pattern is an important pattern in Object-Oriented-Programming, it empowers us to delegate the creation of Objects to another Object which must not be known at design and/or compile time. That allows us to use Objects which have not been created by us but merely "provided" to us by an, for us unknown, implementation.
Like an onion
JVx is separated into different layers, with the UI layer being at the top and of the most concern to users.
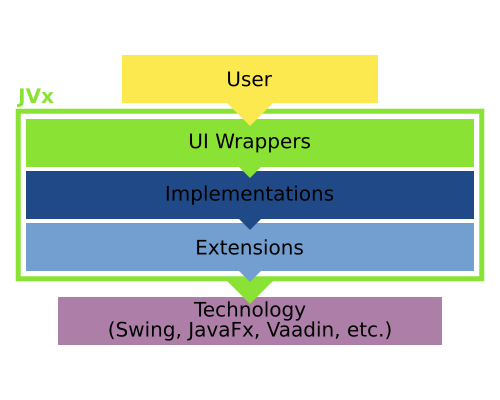
Technology
Obviously, the first one in the chain is the so called "technology" layer. It represents the UI technology, for example Swing, JavaFX or Vaadin, which is used to power the JVx application.
To put it into a more simple term:
Extension
Next comes the extension layer, components from the technology are extended to support needed features of JVx. This includes creating bindings for the databook, additional style options and changing of behavior if necessary. From time to time this also includes creating components from scratch if the provided ones do not meet the needs or there simply are none with the required functionality. For the most part, we do our best that these layers can be used without JVx, meaning that they represent a solitary extension to the technology. A very good example is our JavaFX implementation, which compiles into two separate jars, the first being the complete JVx/JavaFX stack, the second being stand-alone JavaFX extensions which can be used in any application and without JVx.
Theoretically one can skip this layer and directly jump to the Implementation layer, but so far it has proven necessary (for cleanliness of the code and object structure and sanity reasons) to create a separate extension layer.
Implementation
After that comes the implementation layer. The extended components are extended to implement JVx interfaces. This is some sort of "glue" layer, it binds the technology or extended components against the interfaces which are provided by JVx.
UI
Last but for sure not least is the UI layer, which wraps the implementations. It is completely Implementation independent, that means that one can swap out the stack underneath:
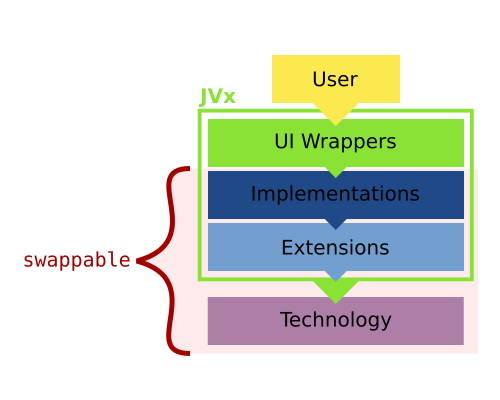
This is achieved because the UI layer is not extending the Implementation layer, but wrapping instances provided by the factory. It is oblivious to what Technology is actually underneath it.
SwingButton resource = SwingFactory.createButton()
Why is the UI layer necessary?
It isn't, not at all. The Implementations could be used directly without any problems, but having yet another layer has two key benefits:
- It allows easier usage.
- It allows to add Technology independent features.
By wrapping it one more time we gain a lot of freedom which we would not have otherwise, when it comes to features as when it comes to coding. The user does not need to call the factory directly and instead just needs to create a new object:
Internally, of course, the Factory is called and an implementation instance is created, but that is an implementation detail. If we would use the implementation layer directly, our code would either need to know about the implementations, which doesn't follow the Single-Sourcing principle:
It also would be possible to directly use the factory (but this isn't modern coding style):
Both can be avoided by using another layer which does the factory calls for us:
{
private IButton resource;
public UIButton()
{
resource = UIFactoryManager.getFactory().createButton();
}
public void someInterfaceMethod()
{
resource.someInterfaceMethod();
}
}
Additionally this layer allows us to implement features which can be technology independent, our naming scheme, which we created during stress testing of an Vaadin application, is a very good example of that. The names of the components are derived in the UI layer without any knowledge of the underlying Technology or Implementation.
Also it does provide us (and everyone else of course) with a layer which allows to rapidly and easily build compound components out of already existing ones, like this:
{
private IButton button = null;
private ILabel label = null;
public LabeledButton ()
{
super();
initializeUI();
}
private void initializeUI()
{
button = new UIButton();
label = new UILabel();
setLayout(new UIBorderLayout());
add(label, UIBorderLayout.LEFT);
add(button, UIBorderLayout.CENTER);
}
}
Of course that is not even close to sophisticated, or a good example for that matter. But it shows that one can build new components out of already existing ones without having to deal with the Technology or Implementation at all, creating truly cross-technology controls.
The Factory
The heart piece of the UI layer is the Factory, which is creating the Implemented classes. It's a rather simple system, a Singleton which is set at the beginning to the Technology specific factory which can be retrieved later:
UIFactoryManager.setFactoryInstance(new SwingFactory());
// Or alternately:
UIFactory.getFactoryInstance(SwingFactory.class());
// Later inside the UI wrappers.
IButton button = UIFactory.getFactory().createButton();
The complexity of the implementation of the factory is technology dependent, but for the most part it is devoid of any logic:
{
@Override
public IButton createButton()
{
SwingButton button = new SwingButton();
button.setFactory(this);
return button;
}
}
It "just returns new objects" from the implementation layer. That's about it when it comes to the factory, it is as simple as that.
Piecing it together
With all this in mind, we know now that JVx has swappable implementations underneath its UI layer for each technology it utilizes:
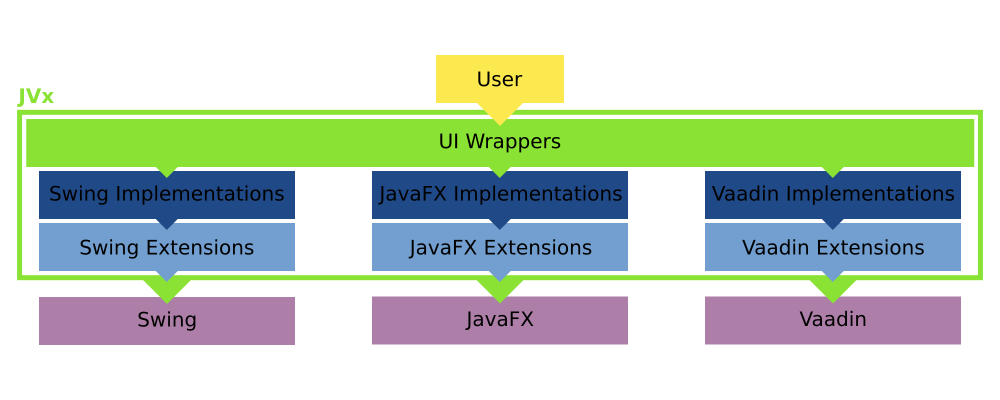
Changing between them can be as easy as setting a different factory. I say "can", because that is only true for Swing, JavaFX and similar technologies, Vaadin, obviously, requires some more setup work. I mean, theoretically one could embed a complete application server and launch it when the factory for Vaadin is created, allowing the application to be basically stand-alone and be started as easily as a Swing application. That is possible.
What else?
That is how JVx works in regards to the UI layer. It depends on "technology specific stacks" which can be swapped out and implemented for pretty much every GUI framework out there. We currently provide support for Swing, JavaFX and Vaadin, but we also had implementations for GWT and Qt. Additionally we do support a "headless" implementation which allows to use lightweight objects which might be serialized and send over the wire without much effort.
Adding a new Technology
Adding support for a new Technology is as straightforward as one can imagine, simply creating the Extensions/Implementations layers and implementing the factory for that Technology. Giving a complete manual would be out for scope for this post, but the most simple approach to adding a new stack to JVx is to start with stubbing out the IFactory and implementing IWindow. Once that one window shows up, it's just implementing one interface after another in a quite straightforward manner. And in the end, your application can switch to yet another GUI framework without the need to change your code.
![]() API, Development, Information | rzenz | 07/12/2016 |
API, Development, Information | rzenz | 07/12/2016 | ![]() Comments (1)
Comments (1)

 RSS-Feed
RSS-Feed