Let's talk about custom components, and how to create them.
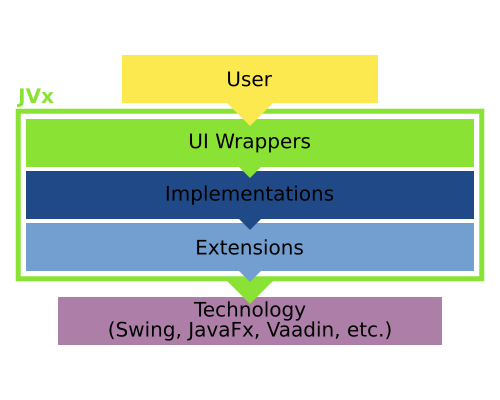
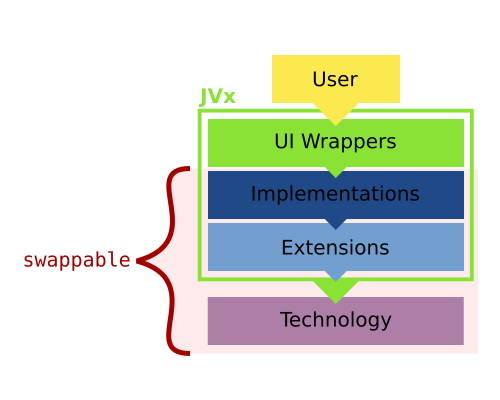
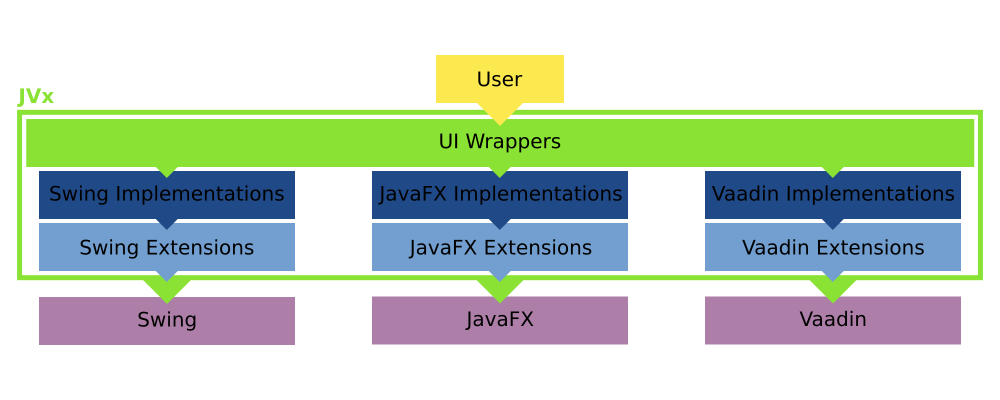
The GUI of JVx
We've previously covered how the GUI of JVx works, and now we will have a look on how we can add custom components to the GUI.
In the terminology of JVx there are two different kinds of custom components:
- UI based
- Technology based
We will look at both, of course.
Custom components at the UI layer
The simplest way to create custom components is to extend and use already existing UI classes, like UIPanel or UIComponent. These custom components will be Technology independent because they use Technology independent components, there is no need to know about the underlying Technology. You can think of those as a "remix" of already existing components.
The upside is that you never have to deal with the underlying Technology, the downside is that you can only use already existing components (custom drawing is not possible, for example).
Let's look at a very simple example, we will extend the UILabel to always display a certain postfix along with the set text:
public class PostfixedLabel
extends UILabel
{
private String postfix
= null;
// We must store the original text so that we can return
// it if requested. Otherwise we could only return the text
// with the appended postfix, which works unless the postfix
// changes.
private String text = null;
public PostfixedLabel()
{
super();
}
public PostfixedLabel(String pText)
{
super(pText);
}
public PostfixedLabel(String pText, String pPostfix)
{
super(pText);
setPostfix(pPostfix);
}
@Override
public String getText()
{
return text;
}
@Override
public void setText(String pText)
{
text = pText;
if (!StringUtil.isEmpty(postfix) && !StringUtil.isEmpty(pText))
{
// We translate the text and the postfix now separately,
// the underlying label will obviously try to translate
// the concatenated version.
super.setText(translate(pText) + translate(postfix));
}
else
{
super.setText(pText);
}
}
public String getPostfix()
{
return postfix;
}
public void setPostfix(String pPostfix)
{
postfix = pPostfix;
// If the postfix changed, we must update the text.
setText(text);
}
}
It will be treated just like another label, but every time a text is set, the postfix is appended to it.
Another example, we want a special type of component, one that always does the same but will be used in many different areas of the application, it should contain a label and two buttons. The best approach for a custom component which should not inherit any specific behavior is to extend UIComponent:
public class BeepComponent
extends UIComponent
{
public BeepComponent
()
{
super(new UIPanel
());
UIButton highBeepButton
= new UIButton
("High Beep");
highBeepButton.
eventAction().
addListener(Beeper
::playHighBeep
);
UIButton lowBeepButton
= new UIButton
("Low Beep");
highBeepButton.
eventAction().
addListener(Beeper
::playLowBeep
);
UIFormLayout layout
= new UIFormLayout
();
uiResource.setLayout(layout);
uiResource.add(new UILabel("Press for beeping..."), layout.getConstraints(0, 0, -1, 0));
uiResource.add(highBeepButton, layout.getConstraints(0, 1));
uiResource.add(lowBeepButton, layout.getConstraints(1, 1));
}
}
So we extend UIComponent and set a new UIPanel as UIResource on it, which we can use later and which is the base for our new component. After that we added a label and two buttons which will play beep sounds if pressed. This component does not expose any specific behavior as it extends UIComponent, it only inherits the most basic properties, like background color and font settings, yet it can easily be placed anywhere in the application and will perform its duty.
Custom controls at the Technology layer
The more complex option is to create a custom component at the Technology layer. That means that we have to go through a multiple steps process to create and use the component:
- Create an interface for the functionality you'd like to expose
- Extend the Technology component (if needed)
- Implement the necessary interfaces for JVx
- Extend the factory to return the new component
- Create a UIComponent for the new component
- Use the new factory
I will walk you through this process, step by step.
The upside is that we can use any component which is available to us in the Technology, the downside is that it is quite some work to build the correct chain, ideally for every technology.
Creating an interface
The first step is to think about what functionality the component should expose, we will use a progress bar as example. We don't want anything fancy for now, a simple progress bar on which we set a percent value should be more than enough:
/**
* The platform and technology independent definition for a progress bar.
*/
public interface IProgressBar extends IComponent
{
/**
* Gets the current value, in percent.
*
* @return the current value. Should be between {@code 0} and {@code 100}.
*/
public int getValue();
/**
* Sets the current value, in percent.
*
* @param pValue the value. Should be between {@code 0} and {@code 100}.
*/
public void setValue(int pValue);
}
Might not be the most sophisticated example (especially in regards to documentation) but it will do for now. This interface will be the foundation for our custom component.
Extending the component, if needed
We will be using Swing and the JProgressBar for this example, so the next step is to check if we must add additional functionality to the Technology component. In our case we don't, as we do not demand any behavior that is not provided by JProgressBar, but for the sake of the tutorial we will still create an extension on top of JProgressBar anyway.
public class ExtendedProgressBar extends JProgressBar
{
public ExtendedProgressBar(int pMin, int pMax)
{
super(pMin, pMax);
}
}
Within this class we could now implement additional behavior independent of JVx. For example, we provide many extended components for Swing, JavaFX and Vaadin with additional features but without depending on JVx. The extension layer is the perfect place to extend already existing components with functionality which will be used by, but is not depending on, JVx.
Creating the Implementation
The next step is to create an Implementation class which allows us to bind our newly extended JProgressBar to the JVx interfaces. Luckily there is the complete Swing Implementation infrastructure which we can use:
public class SwingProgressBar<ExtendedProgressBar> extends SwingComponent
implements IProgressBar
{
public SwingProgressBar()
{
// We can hardcode the min and max values here, because
// we do not support anything else.
super(new ExtendedProgressBar(0, 100));
}
@Override
public int getValue()
{
return resource.getValue();
}
@Override
public void setValue(int pValue)
{
resource.setValue(pValue);
}
}
That's it already. Again, in this case it is quite simple because we do not expect a lot of behavior. The implementation layer is the place to "glue" the component to the JVx interface, implementing missing functionality which is depending on JVx and "translating" and forwarding values and properties.
Extending the factory
Now we must extend the Factory to be aware of our new custom component, that is equally simple as our previous steps. First we extend the interface:
public interface IProgressBarFactory extends IFactory
{
public IProgressBar createProgressBar();
}
And afterwards we extend the SwingFactory:
public class ProgressBarSwingFactory extends SwingFactory
implements IProgressBarFactory
{
@Override
public IProgressBar createProgressBar()
{
SwingProgressBar progressBar = new SwingProgressBar();
progressBar.setFactory(this);
return progressBar;
}
}
Again, it is that easy.
Creating the UIComponent
So that we can use our new and shiny progress bar easily, and without having to call the factory directly, we wrap it one last time in a new UIComponent:
public class UIProgressBar<IProgressBar> extends UIComponent
implements IProgressBar
{
public UIProgressBar()
{
// We'll assume that, whoever uses this component,
// is also using the correct factory.
super(((IProgressBarFactory)UIFactoryManager.getFactory()).createProgressBar());
}
@Override
public int getValue()
{
return uiResource.getValue();
}
@Override
public void setValue(int pValue)
{
uiResource.setValue(pValue);
}
}
Nearly done, we can nearly use our new and shiny component in our project.
Using thecustom factory
Of course we have to tell JVx that we want to use our factory, and not the default one. Depending on the technology which is used, this has to be done at different places:
Swing and JavaFX
Add the factory setting to the application.xml of the application:
<Launcher.uifactory>your.package.with.custom.components.SwingProgressBarFactory</Launcher.uifactory>
Vaadin
Add the following setting to the web.xml under the WebUI Servlet configuration:
<init-param>
<param-name>Launcher.uifactory</param-name>
<param-value>your.package.with.custom.components.VaadinProgressBarFactory</param-value>
</init-param>
Using our new component
And now we are done, from here we can use our custom component like any other.
UIProgressBar progressBar
= new UIProgressBar
();
progressBar.
setValue(65
);
// Skip
add(progressBar, constraints);
Wrapping custom components with UICustomComponent
There is a third way to have Technology dependent custom components in JVx, you can wrap them within a UICustomComponent:
JProgressBar progressBar
= new JProgressBar(0, 100
);
progressBar.
setValue(100
);
UICustomComponent customProgressBar = new UICustomComponent(progressBar);
// Skip
add(customProgressBar, constraints);
This has the upside of being fast and easy, but the downside is that your code has to know about the currently used Technology and is not easily portable anymore.
Conclusion
As you can see, there are multiple ways of extending the default set of components which are provided by JVx, depending on the use case and what custom components are required. It is very easy to extend JVx with all the components one does require.
")
")
")
")









 RSS-Feed
RSS-Feed